주가 관련 데이터셋 받기
Yahoo Finance - Stock Market Live, Quotes, Business & Finance News
At Yahoo Finance, you get free stock quotes, up-to-date news, portfolio management resources, international market data, social interaction and mortgage rates that help you manage your financial life.
finance.yahoo.com
으로 접속하셔서, 원하는 종목을 검색한다.
검색 결과 페이지 내에서, Historical Data를 클릭한다.
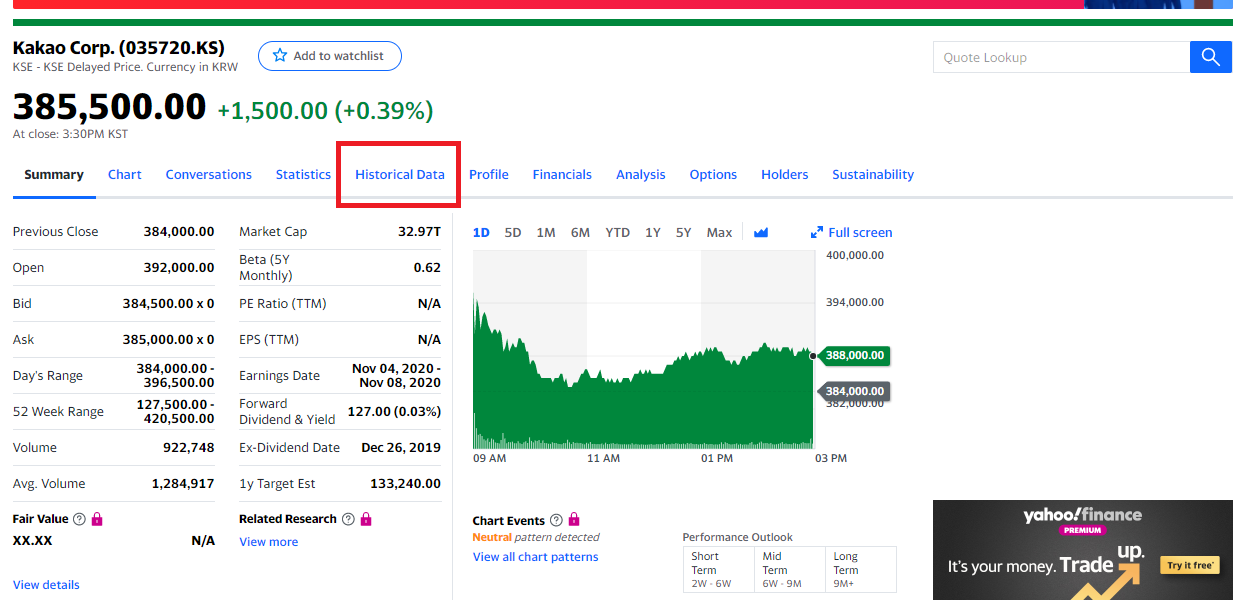
1. Time Period를 클릭하여
2. 원하는 기간을 설정 후, (5Y : 5년, Max : 최대 추천)
3. Apply 버튼을 누른다.
4. 다운로드한다.
다운로드한 데이터는, 파일명으로 바꾸어 파이썬 환경에 저장을 해둔다.
다운로드하기 귀찮으신 분들은 아래 데이터를 사용하시면 됩니다.
첫 번째는 5년 치, 두 번째 꺼는 10년 치 카카오 주식 정보 데이터입니다.
필요 모듈 호출
import pandas as pd
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dropout, Dense, Activation
from pandas.io.parsers import read_csv
파일 업로드 (구글 코랩 사용자만, 다른 환경 사용 시 생략)
from google.colab import files
uploaded = files.upload()
파일 선택 후, 등록
예제에서는 kakao.csv를 이용
CSV 파일 읽기 (파일 이름)
data = pd.read_csv('kakao.csv')구글 코랩 사용자가 아닐 경우, 현재 실행하는 파이썬 프로그램 디렉토리 내에 csv파일 저장할 것! 다른 디렉토리에서 사용 시,
data = pd.read_csv('{파일경로}/kakao.csv')
데이터 확인
data.head()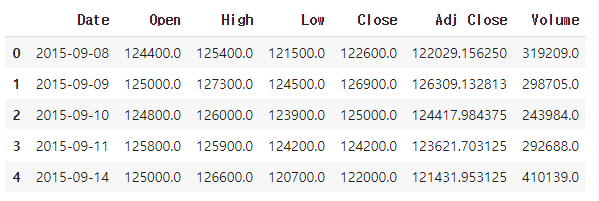
데이터 중 Null 값 제거하기
주가 관련 파일을 보면 다음과 같이 Null 값이 종종 있습니다.
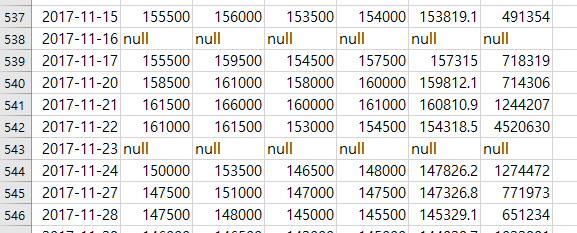
dropna 함수를 사용하여 null을 가진 행 (axis=0) 삭제
data = data.dropna(axis=0)제거를 안 하면, model 훈련 중, 에러를 유발합니다.
고가와 저가의 중간 값으로, mid price 구하기
고가와 저가를 변수로 이용해도 되지만, 예제에서는 중간값으로 접근
high_price = data['High'].values
low_price = data['Low'].values
mid_price = (high_price + low_price) / 2
50일씩 나누어 분리
데이터들을 첫날부터, 50일씩 끊어서 저장
예) [ [0~50일], [1~51일], [2~52일], [3~53일]....... ]
(why? 50일 치 데이터를 가지고 51일째 되는 날의 주가를 예측하기 위해서)
day_divided = 50
day_length = day_divided + 1
day_result = []
for i in range(len(mid_price) - day_length):
day_result.append(mid_price[i: i + day_length])
분리된 데이터 확인
print("전체 데이터 Length : ", len(data))
print("나눈 데이터 Length : ", len(day_result))
print("나눈 데이터 0번째 : ")
print(day_result[0])
print(day_result[1])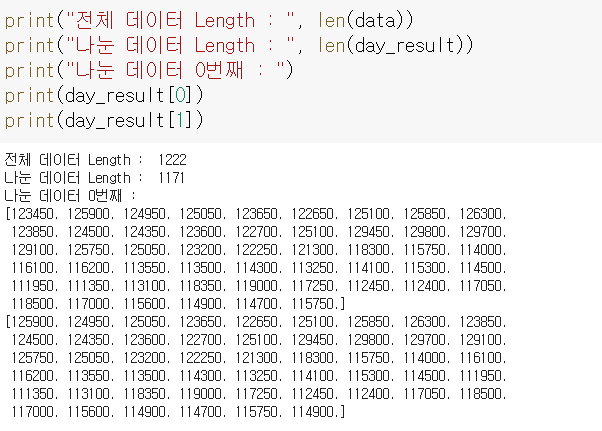
데이터 정규화(Normalized)
50일씩 나누었던 데이터들을 첫날 기준으로 정규화 진행
(첫날을 0으로 만들고, 나머지 날들은 그 비율로 나누어 정규화)
norm_result = []
for section in day_result:
norm_section = [((float(p) / float(section[0])) - 1) for p in section]
norm_result.append(norm_section)
day_result = np.array(norm_result)
분리된 데이터 정규화 결과 확인
print(day_result[0])
데이터셋 정의하기
전체 데이터중 학습 데이터(train_data)는 90%, 테스트 데이터(test_data)는 10% 로 나눔.
데이터가 많지 않아 학습 데이터 비중을 높임.(검증 데이터 사용 x)
train_data_rate = 0.9
boundary = round(day_result.shape[0] * train_data_rate)
train_data = day_result[:boundary, :]
test_data = day_result[boundary:, :]
데이터셋 분리하기
위에서 설정한 train data와 test data를 1차원으로 바꾸고, 각 데이터 0~49번째 가격정보는 x_data, 마지막 50번째는 y_data로 설정
(why? 각 데이터 0~49번째 가격 정보를 가지고, 50번째 가격 정보를 예측하기 위해)
x_train = train_data[:, :-1]
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
y_train = train_data[:, -1]
x_test = test_data[:, :-1]
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
y_test = test_data[:, -1]
데이터셋 확인하기
x_train.shape, x_test.shape((1054, 50, 1), (117, 50, 1))
모델 만들기
LSTM, 순환 신경망(RNN) - 순서가 있는 데이터(소리, 언어, 날씨, 주가)처럼 시간의 변화에 함께 변화하면서 그 영향을 받을 때 사용.
(첫 번째 인자 : 메모리 셀의 개수)
(return_sequences=True : 모든 입력에 대해 출력을 내놓게 한다. return_sequences=False : time sep 마지막에서만 결과를 출력)
(imput_shape : 입력 값)
model = Sequential()
model.add(LSTM(50, return_sequences=True, input_shape=(50, 1)))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(1, activation='relu'))
model.compile(loss='mse', optimizer='sgd')
모델 확인하기
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
lstm (LSTM) (None, 50, 50) 10400
_________________________________________________________________
lstm_1 (LSTM) (None, 64) 29440
_________________________________________________________________
dense (Dense) (None, 1) 65
=================================================================
Total params: 39,905
Trainable params: 39,905
Non-trainable params: 0
_________________________________________________________________
모델 훈련하기
구글 코랩 사용자는 모델 훈련 시, 런타임 환경을 GPU 환경으로 바꾸어 주면 빠르게 처리
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=10,
epochs=15)Epoch 1/20
106/106 [==============================] - 4s 42ms/step - loss: 0.0080 - val_loss: 0.0551
Epoch 2/20
106/106 [==============================] - 4s 41ms/step - loss: 0.0078 - val_loss: 0.0483
Epoch 3/20
106/106 [==============================] - 5s 43ms/step - loss: 0.0077 - val_loss: 0.0451
Epoch 4/20
106/106 [==============================] - 4s 42ms/step - loss: 0.0075 - val_loss: 0.0411
Epoch 5/20
106/106 [==============================] - 4s 42ms/step - loss: 0.0074 - val_loss: 0.0375
Epoch 6/20
106/106 [==============================] - 5s 43ms/step - loss: 0.0073 - val_loss: 0.0359
Epoch 7/20
106/106 [==============================] - 4s 41ms/step - loss: 0.0073 - val_loss: 0.0310
Epoch 8/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0072 - val_loss: 0.0284
Epoch 9/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0072 - val_loss: 0.0274
Epoch 10/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0071 - val_loss: 0.0286
Epoch 11/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0071 - val_loss: 0.0256
Epoch 12/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0071 - val_loss: 0.0240
Epoch 13/20
106/106 [==============================] - 4s 41ms/step - loss: 0.0070 - val_loss: 0.0228
Epoch 14/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0070 - val_loss: 0.0216
Epoch 15/20
106/106 [==============================] - 4s 41ms/step - loss: 0.0070 - val_loss: 0.0223
Epoch 16/20
106/106 [==============================] - 4s 40ms/step - loss: 0.0070 - val_loss: 0.0200
Epoch 17/20
106/106 [==============================] - 4s 42ms/step - loss: 0.0070 - val_loss: 0.0194
Epoch 18/20
106/106 [==============================] - 5s 47ms/step - loss: 0.0070 - val_loss: 0.0213
Epoch 19/20
106/106 [==============================] - 5s 47ms/step - loss: 0.0070 - val_loss: 0.0190
Epoch 20/20
106/106 [==============================] - 5s 46ms/step - loss: 0.0069 - val_loss: 0.0192
모델 예측하기
pred = model.predict(x_test)
예측값과 실제값 비교(with plot)
import matplotlib.pyplot as plt
plot_figure = plt.figure(figsize=(30, 10))
plot_rst = plot_figure.add_subplot(111)
plot_rst.plot(y_test, label='Real')
plot_rst.plot(pred, label='Predict')
plot_rst.legend()
plt.show()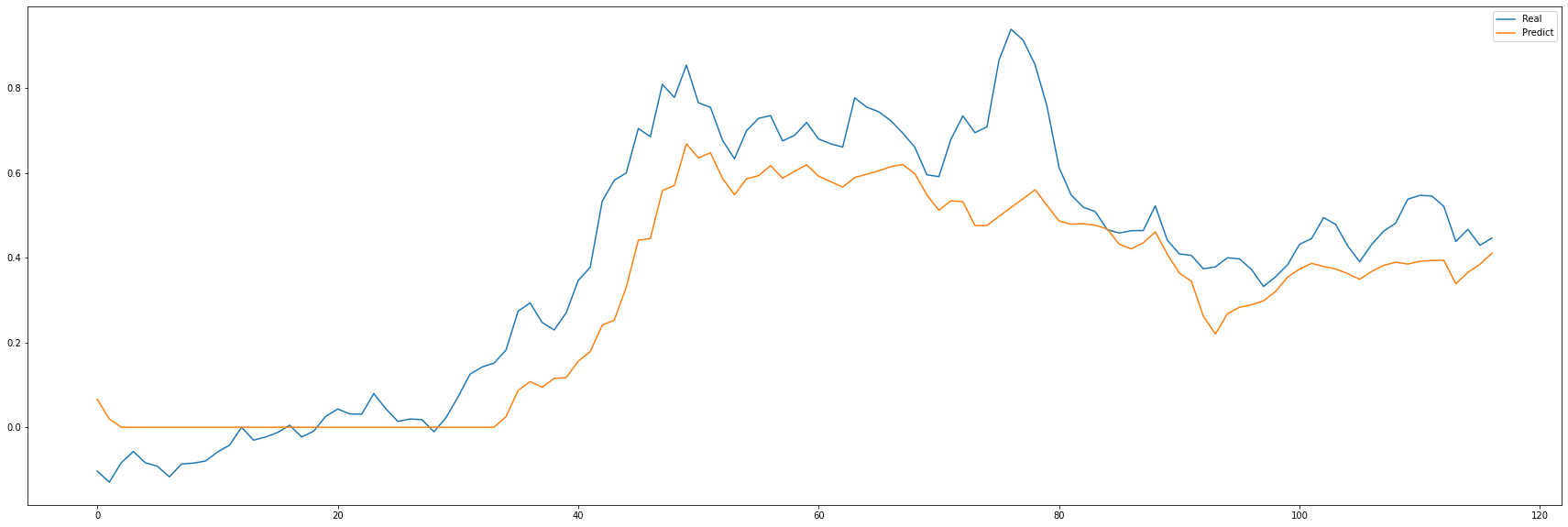
얼추 비슷해 보이지만, 이것을 가지고 주가 예측을 하기에는 리스크가 크다.
아무래도 주가에 영향을 주는 변수는 많이 있기 때문이다. 주식에 관심 있으신 분들은 자신만의 전략을 만들고,
여러 정보를 변수화를 하여 모델을 만들어야 할 것이다.
물론 모든 게 참고 사항이며, 주식은 남들이 주는 고급 정보로 조심스럽게 접근하는 것이 최고인 듯싶다ㅜㅜ!
'AI > Keras-실습' 카테고리의 다른 글
| 케라스 - 닮은꼴 연예인 찾기(with OpenCV, TM)_2 (0) | 2020.09.11 |
|---|---|
| 케라스 - 닮은꼴 연예인 찾기(with OpenCV, TM)_1 (1) | 2020.09.10 |
| 케라스 - 구성 살펴보기(복습) (0) | 2020.09.10 |